I’ve been thinking about the sort of browser-based games I loved to play as a child a lot, essentially “PHP and a database” as a game engine, where navigating the world of the game was done through navigating the site and so on (see the end of this post for some examples if you never had this childhood). I’ve also been thinking about how I’d build one with AWS Lambda and DynamoDB rather than a more traditional hosted server and self-maintained SQL database.
Here I’ll explore how I’d model the inventory of a player in such a game in DynamoDB.
Requirements and prelim design
I want to lean into Single Table Design for this exercise because as I grow the game, I want to be able to perform single queries against multiple table items without being restricted by different types of data. I should be able to remove an item from the inventory and progress a quest in a single operation, for example. It won’t really be that obvious in this exercise, but it will influence our key design.
Also for an inventory I’d like to achieve the following:
- A multi-user system
- Listing a player’s full inventory
- Filtering on inventory item category
- Getting a specific inventory item
- Safely adding/removing items from the inventory
- Some form of trading between players
- “Infinite” inventory capacity
Partition key design
To beat the dead horse of DynamoDB, access patterns must be at the forefront of your design, and I think the choice to have a multi-user system directly affects key design. For good throughput it would be logical to partition on user. Hot partitions won’t occur as a result of many users, and it seems unlikely that a single user would have such high contention in their own use of the system to cause a problem, plus it should be quicker to access related data since DynamoDB items sharing a partition key should be stored together.
Putting the inventory example aside for a moment, we can consider a design where we use username (or email, or something) to form part of a composite partition key. user#rory might be a simple enough partition key for my user data, for example, and a sort key might help us divide categories of data under that. I suggest a composite partition key to aid with single-table design here, as this table may very well hold data that isn’t user oriented as the design grows, so a user#{username} construct seems immediately sensible.
Because I want to use single-table design, I’m going to use a schema with generically named string keys for both partition/hash and sort/range (pk and sk respectively) rather than something like “user_id” and “inventory_id” which would be weird for other data in the system. See the description below:
{
"TableDescription": {
"TableName": "game",
"AttributeDefinitions": [
{ "AttributeName": "pk", "AttributeType": "S" },
{ "AttributeName": "sk", "AttributeType": "S" }
],
"KeySchema": [
{ "AttributeName": "pk", "KeyType": "HASH" },
{ "AttributeName": "sk", "KeyType": "RANGE"}
]
}
}
Inventory Item Schema
I’ll loop back around to other considerations at the end but I’ve ultimately settled on a model of one DynamoDB item per inventory item. While I could partition on user alone, I think it’s probably better to partition on inventory-by-user so that I can take advantage of queries to get all inventory items for a given partition key. The sort key will be used to separate inventory items by their type and their ID. A full example would be:
{
"pk": "inv#rory",
"sk": "weapon#1"
}
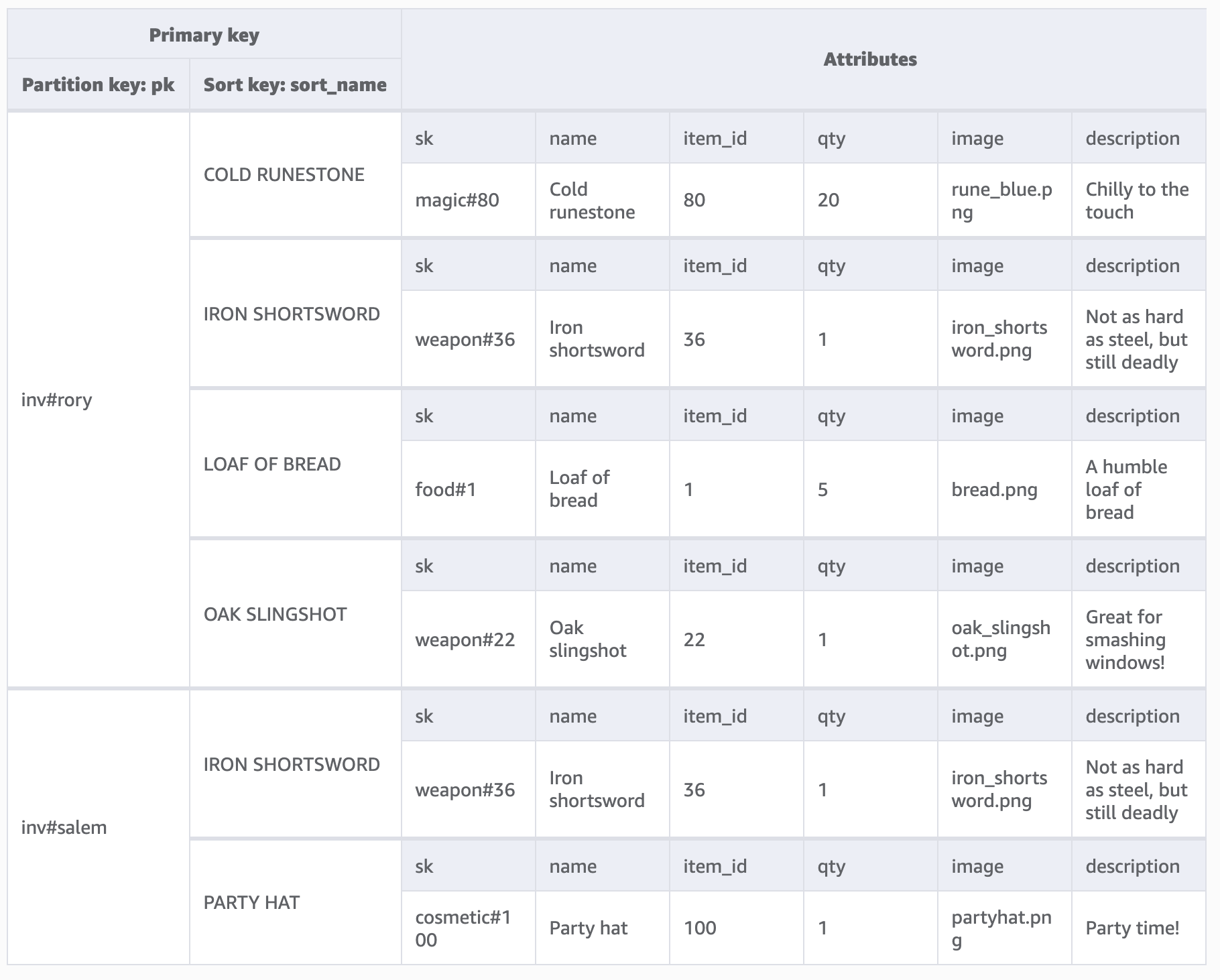
Attributes then become very game item specific. Quantity is probably the bare minimum we need, though I think it could make sense to “pre-join” these records to as much game item metadata as is useful such as the description and image used. A user’s inventory could be loaded “fully” from this table without having to fetch game item data from elsewhere. Cheap things like names and descriptions can be copied (though this introduces complications if we ever want to rename a game item or reword the description, which I’m not sure I would just yet), more data-heavy things like the image used for the game item could be costly to fully pre-join. Perhaps a smarter solution would be to store a reference to the image and have the game logic know how to retrieve that (from local assets, or another more appropriate store like S3). Here’s an aggregate view of what that might look like with some data:
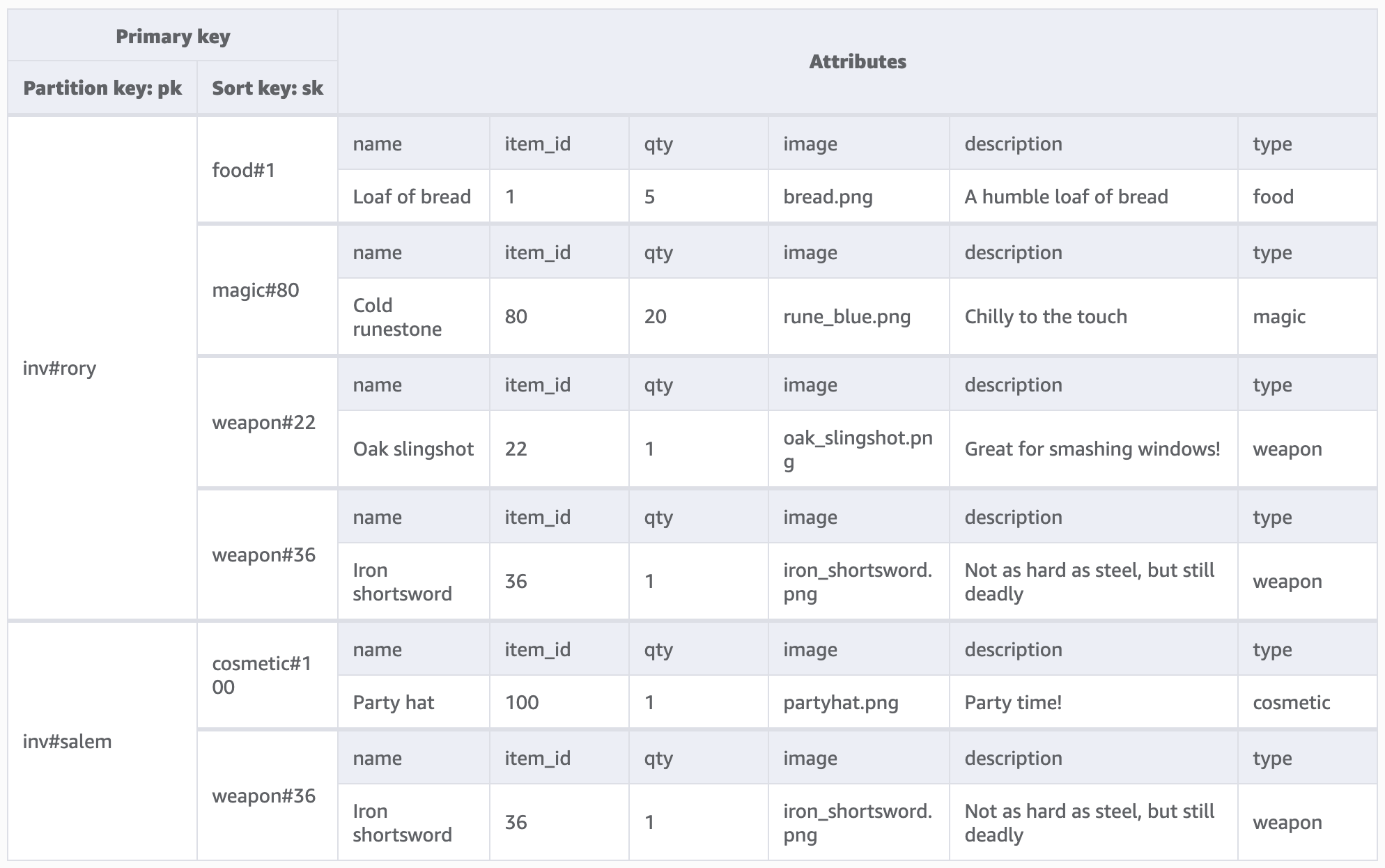
A little aside about my tooling: I’ve used Amazon’s NoSQL Workbench here to model the schema and data for that image. Also using NoSQL workbench I can copy this model to a real DynamoDB instance and use the workbench to validate my access patterns with real queries. I’m using this alongside a dynamodb-local container on my machine.
Getting a player’s full inventory can be done with a simple query operation, note that the RCU consumed will scale based on unique inventory items here. Because of our sort key design, inventory items will be sorted by type and then ID when a player views their inventory, which gives it some kind of logic, but maybe isn’t as easy to browse as alphabetical sorting.
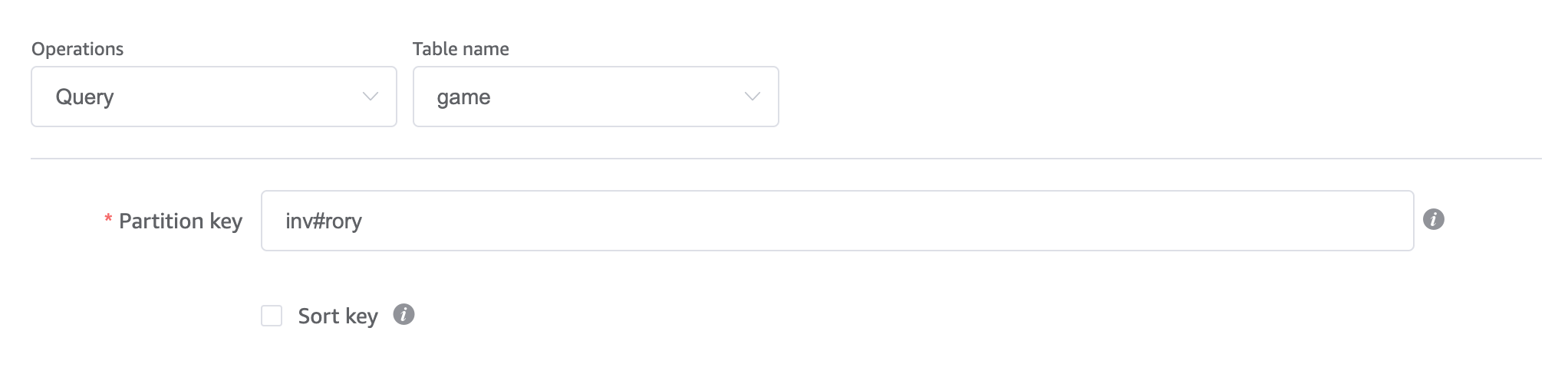
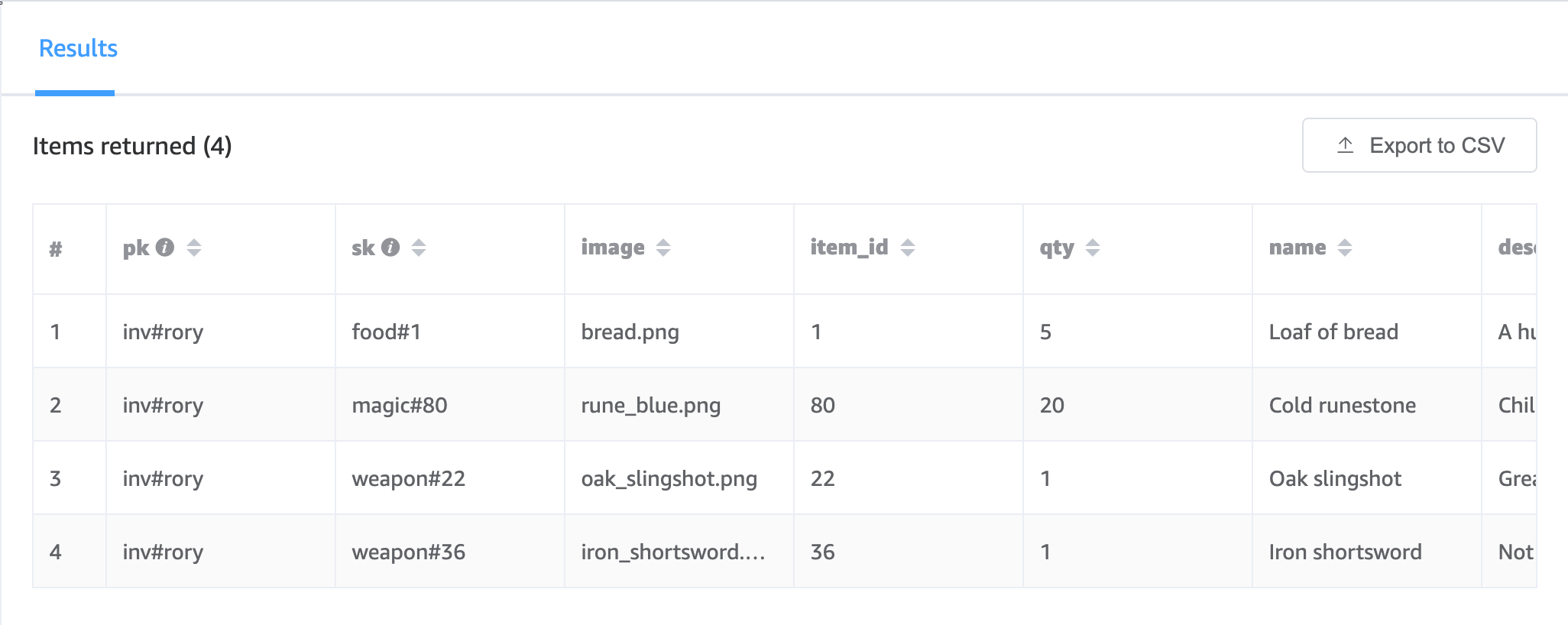
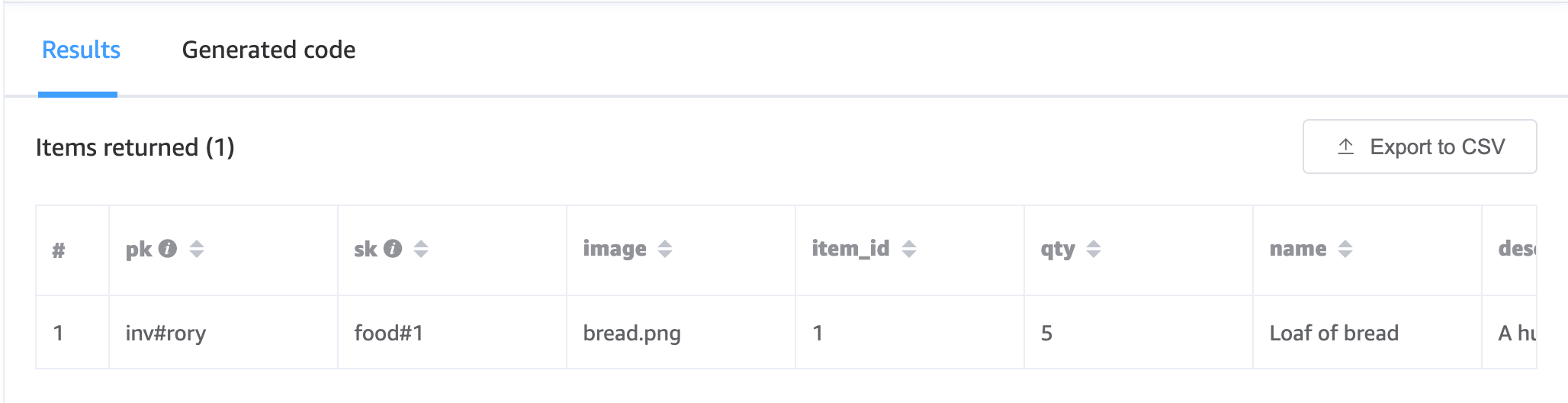
We can fully lean on DynamoDB to validate whether a user has a specific game item simple enough too, but note that we need to know the game item type and ID up front. For a bit of an esoteric scenario, if the player clicks “Make sandwich”, we need to know if they have bread:
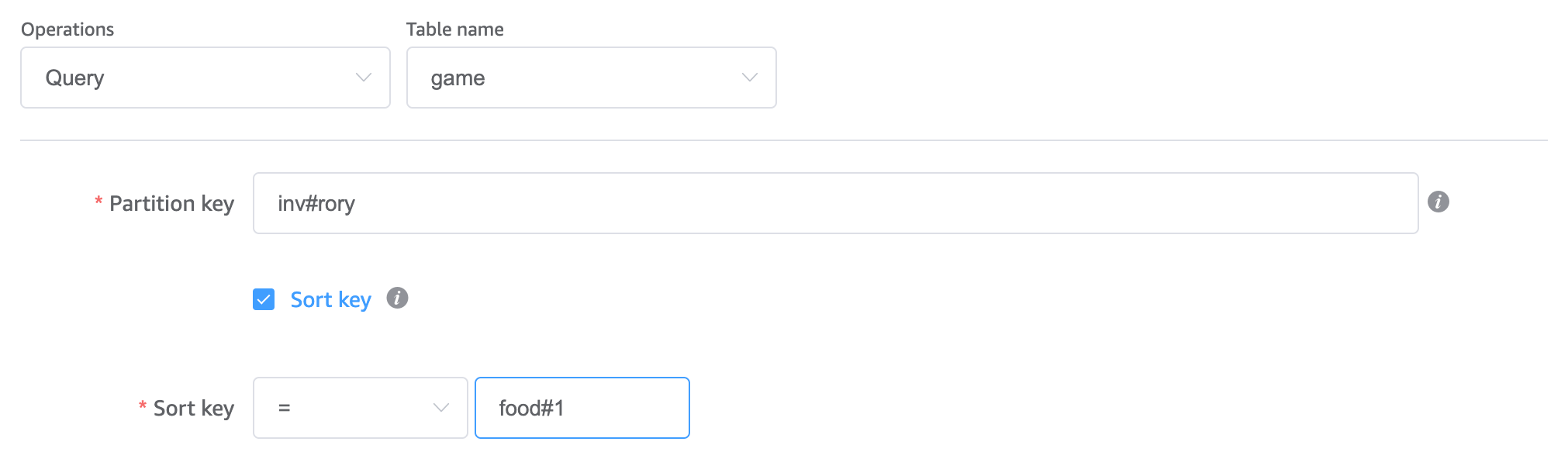
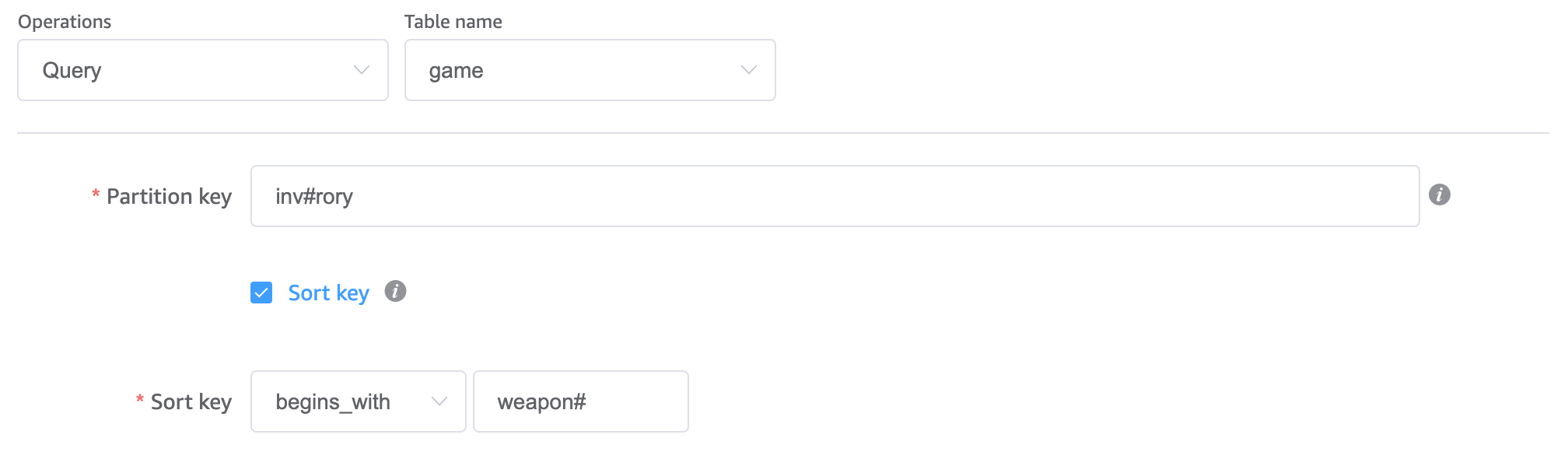
And I can query out a category of game items for scenarios where, say, a user is trying to equip a game item to their hand or browse a subcategory of their inventory. You can only check for sort keys beginning with a value so it’s important that I used the type as a prefix and the ID as a suffix to enable this in the sort key design:
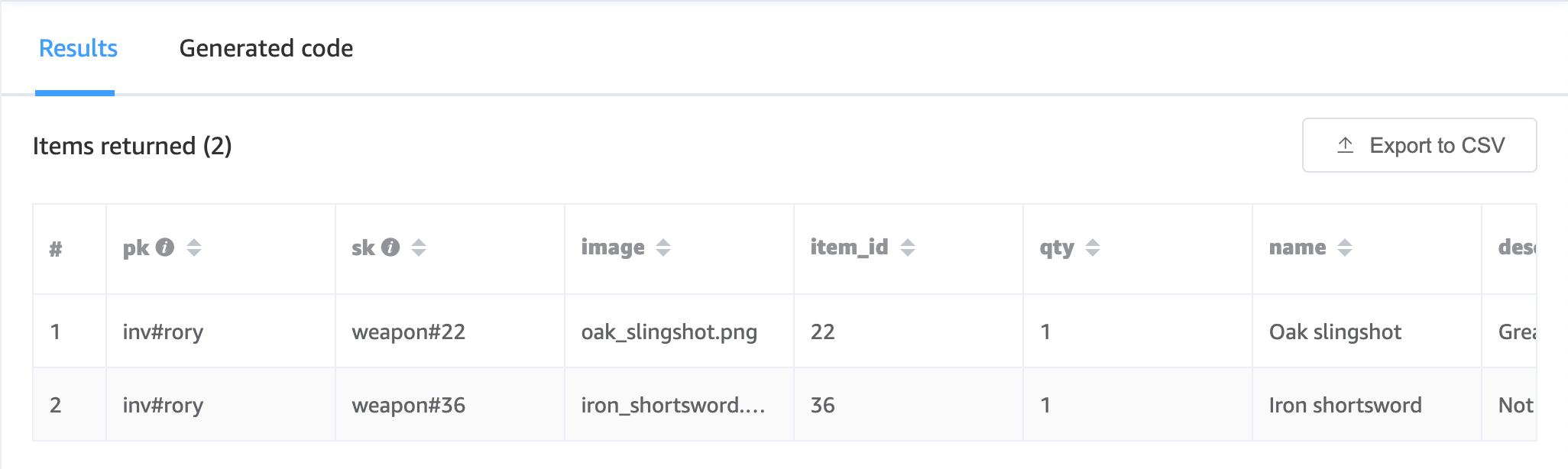
This design overall satisfies an “infinitely” growing inventory. New types are added as new DynamoDB items. New quantity increments an attribute on the DynamoDB item. We can use queries to paginate through a user’s inventory simple enough. Condition expressions on write requests and transactions can be used to make inventory modifications safer, and the finer-grained DynamoDB item design offers low contention on inventory as a whole.
I’m not going to detail it here but “trading” or more generically moving items between inventories could be done with some transactions and condition expressions to ensure that we only move an item that actually exists in an inventory with this design.
Cost prediction
Costs here aren’t super tiny since we’re paying per DynamoDB item (ok, not strictly true, per the docs a query should sum the item sizes to the nearest 4kb and charge on that for reads) rather than a more condensed single-item-inventory (will get to that soon) but assuming a player has one of every item in the game, unless the game has millions of items, there’s still a reasonable cap somewhere here. Targeting an “on-demand” capacity rather than provisioned. I expect reads will be the dominant cost as a user viewing an inventory will require a query of multiple items, but it depends just what the game offers in terms of collecting items too. Bear in mind that a game is very manually driven, this isn’t software that should autonomously be processing tens of thousands of records throughout the day, but something that’s directly reactive to user actions.
0.5 RCU is consumed per 4kb per item per eventually consistent read, doubling for strongly consistent. A user holding 1000 different inventory items would require 500 or 1000 RCU to retrieve the full inventory. I think an eventually consistent inventory is probably appropriate enough but that’s splitting hairs when you consider the costs. At the time of writing, for a london based DynamoDB instance on-demand:
- $1.4846 per million WCU
- $0.297 per million RCU
I make that 3,367,003 RCU required before we break a dollar, so 3,367 full inventory requests and that’s even before you consider that as per the docs, a query operation should charge RCU based on the items in the query response summed to the nearest 4kb (so technically more RCU efficient than individual item retrieval). I don’t think it’ll spiral fast, but we’ll see when my bill comes in.
Other options
Primarily the other option considered was to store the full inventory as an attribute on a single item. Single items can grow up to 400kb so there’s a theoretical “cap” there for inventory size but you could work around it with a few solutions. You could split the inventory into “buckets” using sort keys (so rather than 1 item per inventory item, perhaps 1 item per 100 for example). These buckets could be arbitrary or similar to the previous design, based on item type. In fact an example from amazon’s own documentation proposes a design along those lines. Here’s a bag of considerations for such a model:
- Not infinite unless you use a slightly more complex model to split the inventory into buckets (which then requires more pagination).
- Cannot test if inventory contains item without retrieving full inventory.
- Cannot get and work with single item without retrieving inventory up to that item, possibly full inventory.
- Cost potentially more wasteful in these scenarios if we have to page through others. If other items are significantly large, we pay for the full size.
- Unclear how much more complex query expressions become to completely remove, add, or alter inventory items, or if alterations need to be done in application code.
- More inventory items on a single DynamoDB item could lead to higher contention on it, requiring more transactional processing or optimistic locking to avoid data problems (and then application-side retry mechanisms).
Additional notes
Cost calculation
In spite of all the documentation around it, I’m still a bit shaky on the cost calculations so please don’t sue me if you implement everything I wrote here and get a big bill. It also doesn’t help that the AWS costs page for DynamoDB on-demand talks about request vs capacity units which are a concept in provisioned DynamoDB (RRU/WRU vs RCU/WCU) but I’m sure that’s just a mistake, the calculator seems to use the right terminology and share the same figures.
Going beyond
This satisfies all basic requirements but what about going beyond with some advanced ideas and scenarios?
As mentioned before this design will automatically sort inventories by type first, then inventory item Id. An alphabetically sorted inventory might be easier to browse in some circumstances. We could take advantage of a local secondary index here as we’ll want to use the same partition key (same user’s inventory, different sort). The LSI could point to a sort_name attribute which is a normalised (e.g. upper-cased) variant of the item’s actual name. This would then natively retrieve the items sorted alphabetically by their name.
Inventory item name searching would be another good extension. This would be problematic: if we want to search arbitrary attributes we would need to use a filter expression. Filter has limitations: it is applied after item retrieval but before results are returned to us, we’re charged for all items retrieved regardless of them being filtered out and we’re limited to the maximum items we can retrieve in a single query meaning the filter might not apply to the whole inventory. If we reuse the index above, we can use a query expression on the sort key but we are limited to equality, begins_with or some other comparisons that don’t really make sense. Not exactly a full text search. Such a mechanism could be achieved by using DynamoDB Streams to populate a search index in something like ElasticSearch and then targeting such inventory searches at that external thing if really desired, but it’s much more complex than base DynamoDB usage.
Finally multiple inventories such as banks, shops, even npcs. For a player, multiple inventories could be achieved simply with sort key prefixing e.g. bank#rory or shop#rory. NPCs could have their own usernames, or perhaps a slightly different key design npc#inv#anna. It’s not too dissimilar to having inventories separated by player.
Modeling exercises
I don’t feel super comfortable with my DynamoDB modeling abilities, which was one of the main drivers for trying to sound out my thoughts into the void here. I would like to try and exercise this model in code sometime, if I do that I’ll post an update with any new thoughts. In the meantime while trying to find any input online for a game inventory in DynamoDB (or something similar) I stumbled upon an Amazon’s “DynamoDB Labs” workshop online, which has a couple of modeling exercises: a retail shopping cart and a bank payments system. If this post has been interesting to you and you’d like to try an exercise yourself, consider those.
Game examples
Here’s a handful of browser based games I have played (note that I played a ton more that were so short lived and so long ago that I cannot find any evidence they existed or remember the name):
- Ogame
- Neopets
- Urban Riot (no evidence of this one, played it in school, involved getting drugs and money and guns and doing gang stuff)
- Larkinor Quest
- The Kingdom of Loathing
- Torn