I’ve been digging into the extent of DynamoDB’s “nearly schemaless” nature to find out just how far you can push things. I think it would be very rare and exceptional if you actually need to know the detail in this post, but I found it interesting to dig into some edge cases here, and wanted to write this up as I struggled to find answers for some of the weirder questions I had.
Overview of Schema in DynamoDB
A quick preface, or reminder, is that DynamoDB is often described as “Schemaless except for key schema” - the actual items can be as freeform as you like but your table needs to have a rigid and consistent key schema consisting of:
- If your primary key is composite (using partition and sort keys) or not (only partition key)
- What your key name/s are
- What scalar data type (string/number/binary) your key/s are
When creating a table you basically have two properties to define your schema:
- “KeySchema” - a definition of key names and key types (partition/sort) for the base table
- “AttributeDefinitions” - a definition of key names and data types
The AWS Console abstracts this split away from you a bit, but nonetheless you define your names/data types for your key parts. What’s not obvious here is that “AttributeDefinitions” can define more attributes than just your table key schema but if and only if you are defining schema for keys used by secondary indexes. Still key schema, ultimately. To hammer this home: your base table just treats these as attributes but your secondary indexes (local or global) will need to have the same rigour as a base table in order to operate correctly. Once schema is defined here, DynamoDB will actually validate operations which violate schema - throwing an error if, for example, you use a number for a key which is defined as a string, even for secondary indexes.
An important note on this: You cannot define arbitrary schema for your items (it isn’t just simply discouraged, DynamoDB will actually throw an error if you include an attribute in AttributeDefinitions which is not referenced in KeySchema for the base table or any index).
Secondary indexes
So this lead me to a question: table keys and Local Secondary Index keys are constant for a table’s lifespan. Global Secondary indexes and their keys, however, can be much more dynamically created and deleted. How exactly does DynamoDB enforce schema for these both at and after point of creation?
It turns out the following key behaviours exist:
- GSI Key attributes are not mandatory. If you omit them, the item will simply not project into the index. This is known as building a ‘sparse index’.
- Newly-set GSI key attributes on items must conform to the attribute definition data type now else DynamoDB will error.
- If you Put a new item or replace an existing one, any/all GSI keys defined must be the defined type.
- If you Update an item to add a GSI key attribute, it must be the defined type
- If your GSI uses a composite key but you only add one key part to an item, the item may not be projected but you still have to conform to the attribute type
- Existing items with existing key attributes will not be validated.
- If the attributes match defined schema exactly, then the items will be projected into the index during the “Backfilling” phase (see Phases of index creation - Backfilling)
- If the attributes do not match key schema, the item will not appear in the index, and the item becomes more difficult to work with.
- You can read and delete these items.
- You cannot Update or replace (Put) these items unless the operation would leave the item in a valid state, even if for example you are updating an unrelated attribute. Violating attributes must be fixed before other write operations can succeed.
Overall I found that very interesting but not particularly surprising. DynamoDB can easily start to validate any item once it has an attribute definition in place. GSIs can be defined regardless of the current validity of items in the table. The validation of key schema only comes into effect from the moment it is defined and it does the least destructive thing possible: permits violating items to continue existing, but forces you to fix them if you wish to edit them.
A final note here would be that key schema type isn’t the only possible violation. DynamoDB places a strict size limit on key attributes (Partition keys: 2048 bytes. Sort keys: 1024 bytes). As above, you could theoretically have items in violation of the size limit at the point of index creation, and they follow the same behaviours as type violations.
Time to live
DynamoDB also supports a Time To Live concept - you can set a given name as the “Time To Live Attribute Name” and then if your item sets that attribute with a timestamp, the item will be automatically deleted by DynamoDB once that timestamp has been elapsed.
This isn’t defined in the same way as key attributes and, perhaps unsurprisingly, isn’t validated at all. It’s a very optimistic system: if you set a numeric timestamp value, it will work. If you don’t set the attribute, or set any other data type in that attribute, DynamoDB will ignore it and not expire the item. No errors, no violations, the feature just won’t work.
I felt this case was worth mentioning as it strikes me as one of the only non-key, non-index use cases where DynamoDB allows defining an attribute up-front for some purpose.
Demonstration
I’d ordinarily provide runnable C# tests against the a dynamodb-local container here, but it does not behave close enough to the live service here. Instead, I’ll talk through and provide some AWS CLI commands below to demonstrate different scenarios. They should all be easily runnable if you want to replicate my testing.
A word of warning at this point: This is going to be a very long series of annotated AWS CLI commands, all reproducible examples of the behaviour already described above. Probably quite a dry read unless you really care. If you are satisfied that everything I’ve written makes sense and you can believe me about how DynamoDB works, then you can happily close this tab and go on with your day doing something far more interesting than reading more of this. No new information will be revealed below, just demonstrated.
Simple validation
With that disclaimer out of the way, if you are reading this sentence then I am pleased to see you don’t value your time and I invite you to begin by creating a table. First, let’s add some schema for a non-key attribute:
aws dynamodb create-table \
--table-name schema-demo \
--billing-mode PAY_PER_REQUEST \
--key-schema AttributeName=pk,KeyType=HASH \
--attribute-definitions AttributeName=pk,AttributeType=S \
AttributeName=ix_pk,AttributeType=S
You’ll note that ix_pk isn’t a key, nor is it defined in a secondary index. Due to that, DynamoDB will error here:
An error occurred (ValidationException) when calling the CreateTable operation: One or more parameter values were invalid: Number of attributes in KeySchema does not exactly match number of attributes defined in AttributeDefinitions
So, you cannot arbitrarily define schema for DynamoDB. This reinforces the schemaless ethos: DynamoDB will only let you define something if absolutely necessary to its operation.
Let’s try that again but add a GSI with ix_pk as its partition key:
aws dynamodb create-table \
--table-name schema-demo \
--billing-mode PAY_PER_REQUEST \
--key-schema AttributeName=pk,KeyType=HASH \
--attribute-definitions AttributeName=pk,AttributeType=S \
AttributeName=ix_pk,AttributeType=S \
--global-secondary-indexes \
"[
{
\"IndexName\": \"gsi\",
\"KeySchema\": [
{\"AttributeName\": \"ix_pk\", \"KeyType\": \"HASH\"}
],
\"Projection\": {\"ProjectionType\": \"ALL\"}
}
]"
This succeeds!
Now for the most basic demonstration of schema validation: violating the base table key. Here we’ve defined pk as a string S, but if I try to Put an item explicitly setting a numeric value N here:
aws dynamodb put-item \
--table-name schema-demo \
--item \
"{
\"pk\": {\"N\": \"123\"}
}"
DynamoDB is going to error with some nicely specific detail:
An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: Type mismatch for key pk expected: S actual: N
Adjacent to this scenario is Putting a valid item for the base table, but violating the schema defined for the GSI key, in very much the same way:
aws dynamodb put-item \
--table-name schema-demo \
--item \
"{
\"pk\": {\"S\": \"test\"},
\"ix_pk\": {\"N\": \"123\"}
}"
Once again, DynamoDB errors with a very detailed response:
An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: Type mismatch for Index Key ix_pk Expected: S Actual: N IndexName: gsi
And to finish off these simple cases, if we create an item in a valid state but then try to do a smaller Update to it which would make it invalid, predictably this too fails:
aws dynamodb put-item \
--table-name schema-demo \
--item \
"{
\"pk\": {\"S\": \"test\"},
\"ix_pk\": {\"S\": \"test\"}
}"
aws dynamodb update-item \
--table-name schema-demo \
--key "{\"pk\": {\"S\": \"test\"}}" \
--update-expression "SET ix_pk = :ix_pk" \
--expression-attribute-values "{\":ix_pk\": {\"N\": \"123\"}}"
An error occurred (ValidationException) when calling the UpdateItem operation: One or more parameter values were invalid: Type mismatch for Index Key ix_pk Expected: S Actual: N IndexName: gsi
Validating a GSI created after data exists
For this scenario I’m going to make the database look a little more interesting. Lets imagine we are an animal rescue, we want to track the animals in our care in our database. We’ll use the following schema:
- pk = Collar id
- name = Animal name
- type = Animal species
- admitted = Date we received animal
Lets write some items in wildly different states of consistency for how admitted was entered into the system. You can imagine this happened through application bugs, bad programming, duplicate code doing different things, or maybe even human data entry error. Our four animals will represent the following states:
admittedas a number, unix epoch style valueadmittedas a string, unix epoch style valueadmittedas a string, ISO standard timestampadmittednot entered
aws dynamodb batch-write-item \
--request-items \
"{
\"schema-demo\": [
{
\"PutRequest\": {
\"Item\": {
\"pk\": {\"S\": \"FRE001\"},
\"type\": {\"S\": \"Dog\"},
\"name\": {\"S\": \"Freddie\"},
\"admitted\": {\"N\": \"174099600\"}
}
}
},
{
\"PutRequest\": {
\"Item\": {
\"pk\": {\"S\": \"ZUZ001\"},
\"type\": {\"S\": \"Dog\"},
\"name\": {\"S\": \"Zuzi\"},
\"admitted\": {\"S\": \"1672563600\"}
}
}
},
{
\"PutRequest\": {
\"Item\": {
\"pk\": {\"S\": \"OTI001\"},
\"type\": {\"S\": \"Rat\"},
\"name\": {\"S\": \"Otis\"},
\"admitted\": {\"S\": \"2024-03-27T07:00:00+0000\"}
}
}
},
{
\"PutRequest\": {
\"Item\": {
\"pk\": {\"S\": \"ED_001\"},
\"type\": {\"S\": \"Rat\"},
\"name\": {\"S\": \"Ed\"}
}
}
}
]
}"
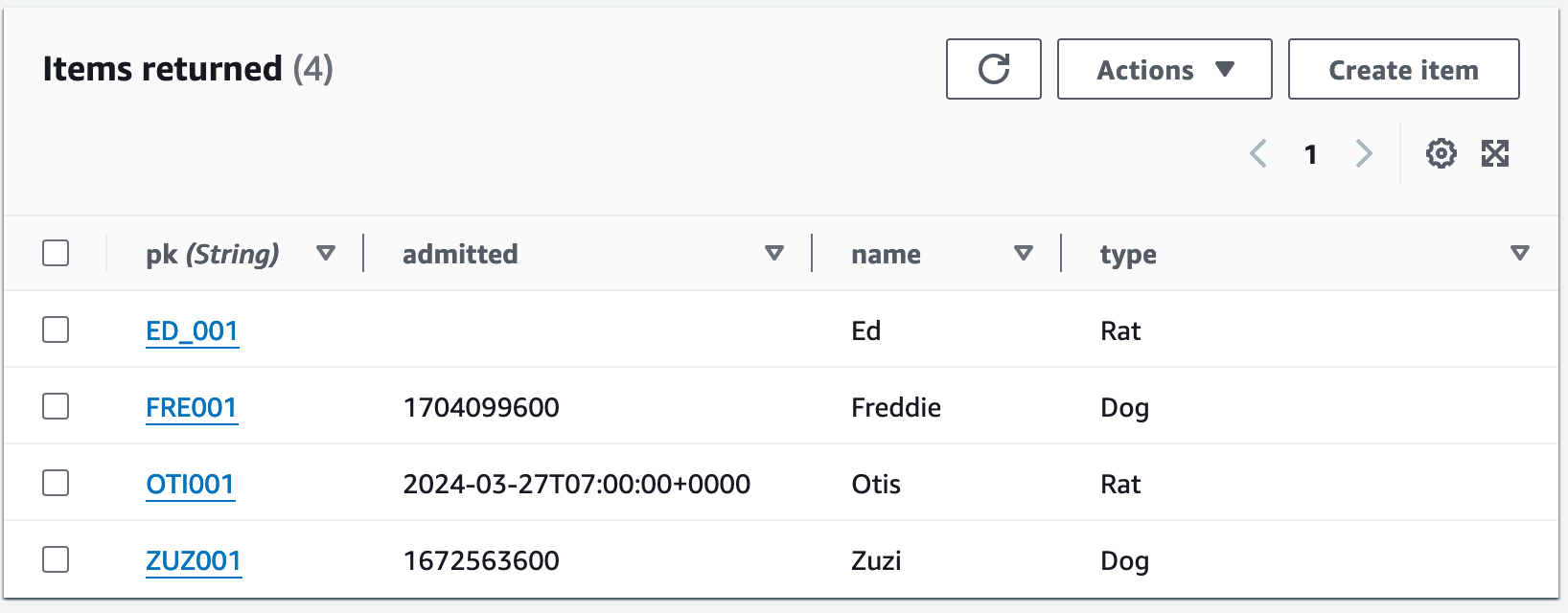
You’ll note the AWS console groups attributes by name only when rendering results of this table, the different data types are ignored .
Next, we need to support a new use case. Users can happily look up individual animals by typing their collar ID into the system, but what if instead they want to access the data by going “I’m looking for a Dog named Zuzi”? We now deliver a GSI to support this, partitioned on type and sorted on admitted.
aws dynamodb update-table \
--table-name schema-demo \
--attribute-definitions AttributeName=type,AttributeType=S \
AttributeName=admitted,AttributeType=N \
--global-secondary-index-updates \
"[
{
\"Create\": {
\"IndexName\": \"animal_type\",
\"KeySchema\": [
{
\"AttributeName\": \"type\",
\"KeyType\": \"HASH\"
},
{
\"AttributeName\": \"admitted\",
\"KeyType\": \"RANGE\"
}
],
\"Projection\": {\"ProjectionType\": \"ALL\"}
}
}
]"
Now begins GSI creation, the table status transitions to UPDATING and this GSI should be listed as CREATING too if you were to describe the table or browse table indexes in the console. Once created, it’ll enter a backfilling phase where it slowly writes all relevant records into the index. Once that’s done and the index is live, we can Scan it to see everything that made it through, which reveals that only the one item which had the attribute set to the defined value type has been projected into the index:
aws dynamodb scan \
--table-name schema-demo \
--index-name animal_type
{
"Items": [
{
"pk": {
"S": "FRE001"
},
"admitted": {
"N": "174099600"
},
"name": {
"S": "Freddie"
},
"type": {
"S": "Dog"
}
}
],
"Count": 1,
"ScannedCount": 1,
"ConsumedCapacity": null
}
Scanning the base table will reveal that all records still exist there, unharmed by the schema change. Now for the interesting bit: if you try to Update an item which violates this new schema, even if your Update does not involve the GSI keys, it will fail, and with a bit of a vague error at that.
aws dynamodb update-item \
--table-name schema-demo \
--key "{\"pk\": {\"S\": \"ZUZ001\"}}" \
--update-expression "SET temperament = :temperament" \
--expression-attribute-values "{\":temperament\": {\"S\": \"FRIENDLY\"}}"
An error occurred (ValidationException) when calling the UpdateItem operation: The update expression attempted to update the secondary index key to unsupported type
There’s no violation in our Update expression, but because the item would fail to write anew now we are told there’s a schema violation (though not exactly what, which I find a bit of a shame given the clarity on previous errors).
You’ll also get an error if you were to simply Get and then Put the item unmodified, which might seem obvious given the above but I wanted to call it out explicitly as it might be typical for you to read items in full, modify in memory, and then Put items in full. Thankfully this time, DynamoDB will return much better error detail, listing the key name, expected/actual types, and index name:
aws dynamodb put-item \
--table-name schema-demo \
--item \
"{
\"admitted\": {\"S\": \"1672563600\"},
\"pk\": {\"S\": \"ZUZ001\"},
\"name\": {\"S\": \"Zuzi\"},
\"type\": {\"S\": \"Dog\"}
}"
An error occurred (ValidationException) when calling the PutItem operation: One or more parameter values were invalid: Type mismatch for Index Key admitted Expected: N Actual: S IndexName: animal_type
It’s worth noting that any items in current violation of new GSI key schema can happily be read or deleted, you are only prevented from writing to them unless your write fixes the violation. Once you do that (either by removing the attribute or fixing the type) you can happily continue updating the item in other ways and it will never enter an invalid state again provided you don’t modify the schema in a way that causes violation again.
Time To Live (TTL)
And a final demo on TTL, lets first add a “ttl” attribute to a couple of records before updating the table, so that one is valid and one is invalid:
aws dynamodb update-item \
--table-name schema-demo \
--key "{\"pk\": {\"S\": \"FRE001\"}}" \
--update-expression "SET #ttl = :ttl" \
--expression-attribute-names "{\"#ttl\": \"ttl\"}" \
--expression-attribute-values "{\":ttl\": {\"N\": \"1704067200\"}}"
aws dynamodb update-item \
--table-name schema-demo \
--key "{\"pk\": {\"S\": \"ED_001\"}}" \
--update-expression "SET #ttl = :ttl" \
--expression-attribute-names "{\"#ttl\": \"ttl\"}" \
--expression-attribute-values "{\":ttl\": {\"S\": \"1704067200\"}}"
Both attributes are using the same value but the latter is stored as a string. If we update the table to enable TTL functionality using this attribute, it succeeds:
aws dynamodb update-time-to-live \
--table-name schema-demo \
--time-to-live-specification Enabled=true,AttributeName=ttl
So, similar to before, we have pre-existing items in various states of violation or non-violation (or are irrelevant, as they are missing the attribute). If we add a new item in violation, this also succeeds:
aws dynamodb put-item \
--table-name schema-demo \
--item \
"{
\"pk\": {\"S\": \"SCA001\"},
\"name\": {\"S\": \"Scampi\"},
\"type\": {\"S\": \"Hamster\"},
\"ttl\": {\"S\": \"A string obviously won't work!\"}
}"
Crucial realisation here: DynamoDB doesn’t care unless your attributes are specifically registered as schema in the table description’s AttributeDefinitions. While DynamoDB has an operational need for this attribute to be numeric in order to provide the feature, it doesn’t care to validate it.
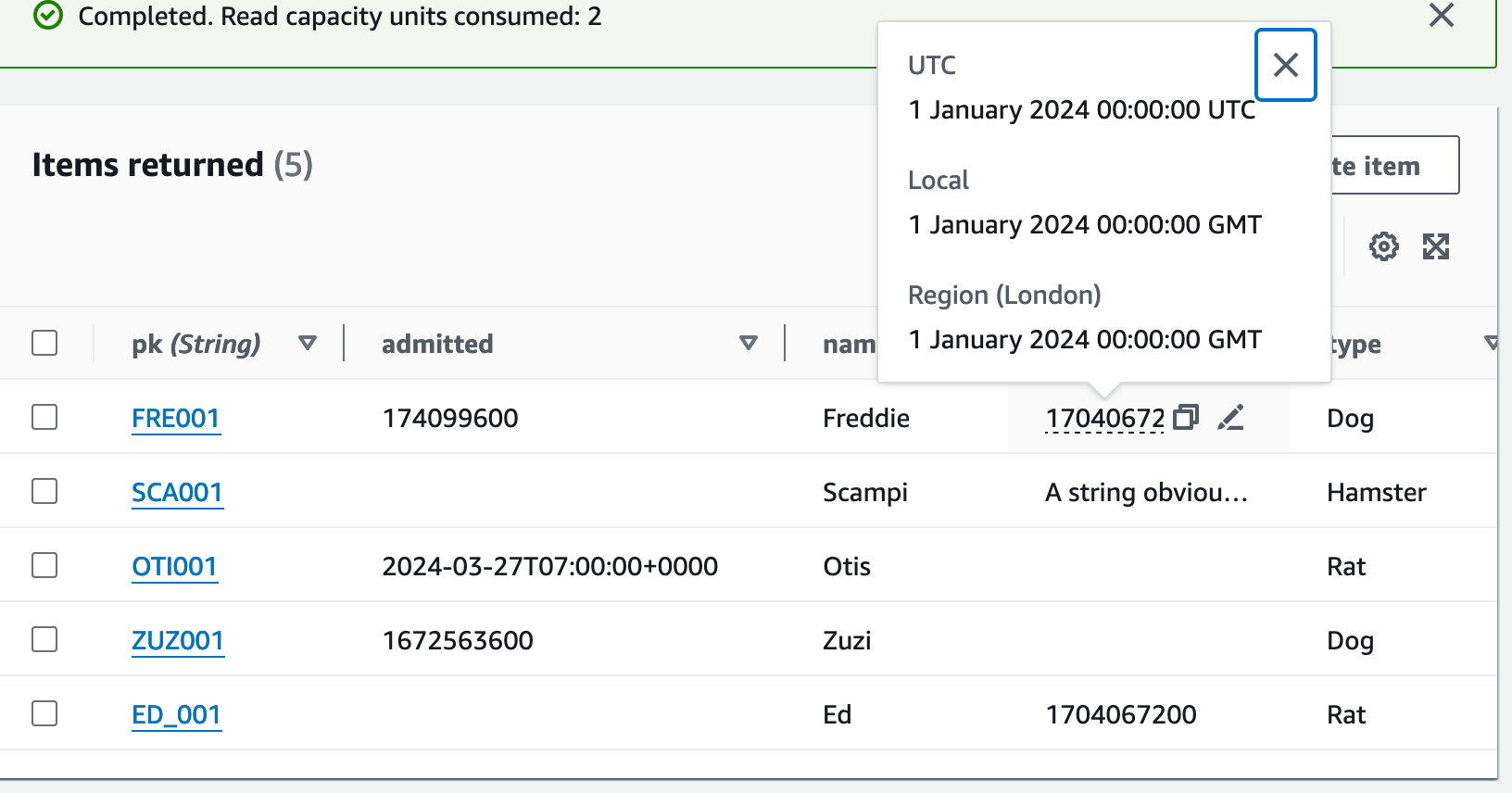
Interestingly, if you view the table data in the AWS console you can see that only the numeric value is underlined. You can hover over it to see the timestamp converted to a human readable date too - this signals that DynamoDB cares about this one and understands it.
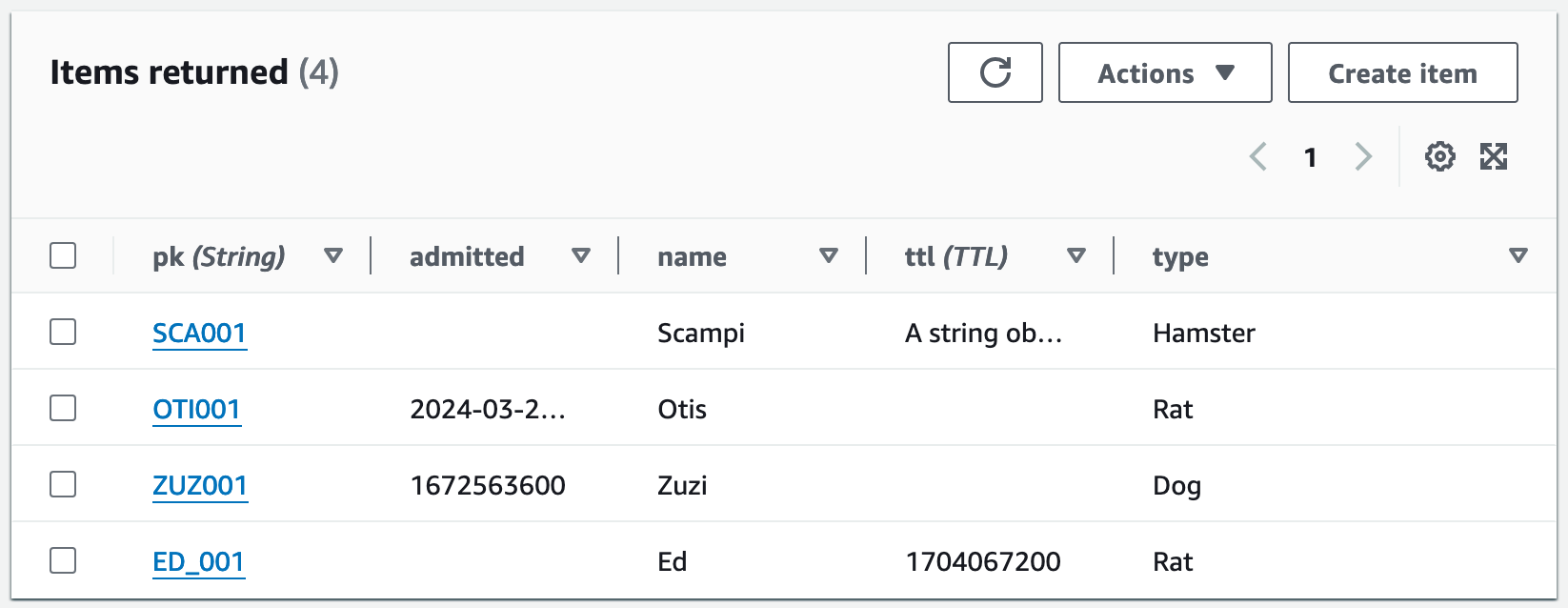
TTL deletions aren’t instant so we’ll have to pause here and check back for this next one. Okay welcome back, time has passed for me but not you here, what a miracle. Anyway, another Scan of the table at this point shows that the valid TTL item has expired, and items with invalid TTLs are effectively ignored forever.
Again, I think it’s pretty obvious that “TTL isn’t Schema” but I wanted to note it explicitly here to underline that DynamoDB only requires you to define key schema, and that is the only schema it enforces.
Can I use and abuse this knowledge to enforce a strong schema for my item design in full then?
Yes I guess you could. Don’t.
Final notes
Removing AttributeDefinitions
Here we defined AttributeDefinitions upfront, proved that you must only supply definitions for key attributes, and when defining a new GSI we supplied new definitions only to support the creation of that GSI.
There’s one case where definitions need removing and that’s if you delete a GSI that was the sole reference of a key attribute. When creating a GSI you only need to provide new definitions, not a complete list, and there is no parameter for removing definitions. DynamoDB seems to clean up the definitions when you do this, meaning that you cannot accidentally leave “dangling schema” here, which is useful and obviously sensible behaviour.
There is no means for removing definitions without also removing an index, and given DynamoDB does not let you arbitrarily add non-key definitions, this too makes sense.
AWS documentation
In turns out, in writing this post, that I finally discovered that there is mention of this behaviour in the AWS documentation somewhere, in a post about detecting and correcting index key violations where it explicitly states:
If an index key violation occurs, the backfill phase continues without interruption. However, any violating items are not included in the index. After the backfill phase completes, all writes to items that violate the new index’s key schema will be rejected.
That feels a little buried as the page seems to be focussed on the tooling provided to resolve such violations, but I appreciate some documentation for this nonetheless, and it’s slightly incorrect that all writes will be rejected, since a write which fixes an item will be permitted.